点上方计算机视觉联盟获取更多干货
仅作学术分享,不代表本公众号立场,侵权联系删除
转载于:作者:Sik-Ho Tsang
编译:ronghuaiyang | AI公园
AI博士笔记系列推荐
周志华《机器学习》手推笔记正式开源!可打印版本附pdf下载链接
导读
从头训练目标检测模型,无需预训练模型。
这篇文章是对DSOD: Learning Deeply Supervised Object Detectors from Scratch,(DSOD),来自复旦大学,清华大学,英特尔实验室中国的回顾。
主要内容:
1. DSOD: 网络结构
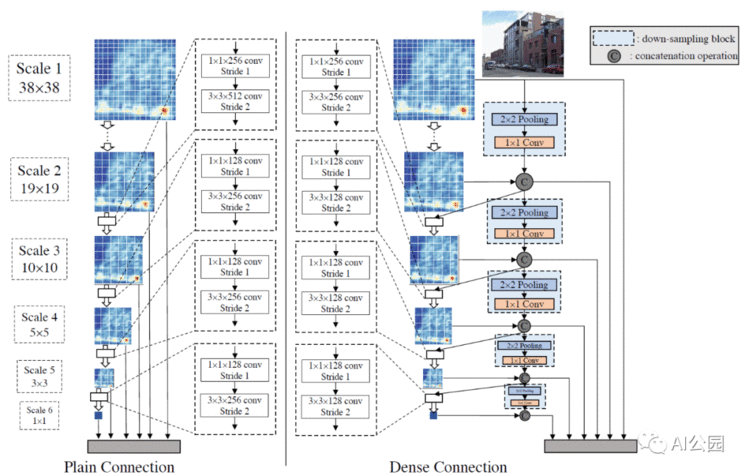
DSOD预测层使用原始的dense结构 (300×300 输入)
所提出的DSOD方法是一个类似于SSD的多尺度proposal-free的检测框架。Proposal-free意味着不存在像Faster R-CNN或者R-FCN这样的区域建议(RPN)网络。DSOD的网络结构可分为两部分:用于特征提取的骨干网络和用于多尺度响应图预测的前端子网络。
1.1. Backbone 子网络
这里使用的backbone 是一个变种的深度监督DenseNet,由1个stem block,4个dense blocks,2个transition层以及2个没有池化层的transition层。
1.2. 前端子网络
前端子网洛(或称DSOD预测层)将多尺度预测响应融合为一个精心设计的dense结构。
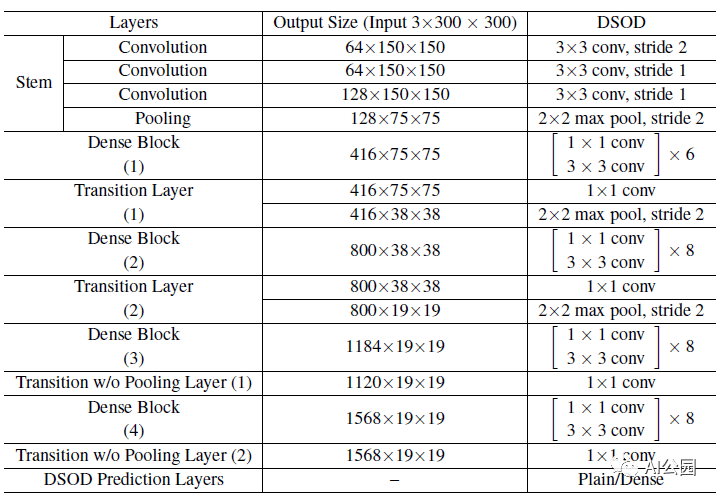
DSOD结构(每个denseblock中,growth rate k = 48)
上表显示了DSOD网络结构的详细信息。
与SSD相同,smooth L1 loss用于定位,softmax loss用于分类。
2. 从头训练的一系列设置
2.1. 原则1:Proposal-Free
我们观察到,在没有预先训练的模型的情况下,只有proposal-free的方法才能成功收敛(而具有RPN的网络则不能)。
基于proposal的方法在预先训练的网络模型中工作得很好,因为在RoI池化之前参数初始化对这些层很好,而从头训练则不是这样。
2.2. 原则2: 深度监督
使用了一种优雅的隐式的深度监督方法叫做dense layer-wise connection,在DenseNet中介绍过。DenseNet中较早的层可以通过跳跃连接从目标函数获得额外的监督。此外,使用了transition w/o Pooling Layer,即不降低最终feature map的分辨率。transition w/o pooling layer消除了DSOD中dense blocks的数量的这种限制。
2.3. 原则3: Stem Block
stem block是由三个3×3卷积层和一个2×2最大池化层组成的,提高了检测性能。与DenseNet中的原设计相比 ( 7×7 conv-layer, stride = 2 followed by a 3×3 max pooling, stride = 2),这里的stem block可以减少从原始输入图像的信息损失。
2.4. 原则4: Dense Prediction结构
如上图所示,对于300×300输入的图像,生成了6个尺度的特征图。
Scale-1 feature maps具有最大的分辨率(38×38),以便处理图像中的小物体。
然后,在两个相邻尺度的特征图之间采用具有bottleneck结构的原始transition层(一个1×1的卷积层用于减少特征图数量,再加上一个3×3的卷积层)。
在SSD这样的普通结构中,每一个后来的尺度直接从邻近的前一个尺度过渡。相比之下,这里用于预测的dense结构,融合了每个尺度的多尺度信息。
在DSOD中,除了scale-1之外,每个尺度的一半特征图是通过一系列的转换层从之前的尺度中学习的,而其余的一半特征图是直接从相邻的高分辨率图中降采样的。
即每个比例尺只学习新特征图的一半,并重用之前的一半。与普通结构相比,这种dense的预测结构可以在更少的参数的情况下获得更准确的结果。
3. 消融研究
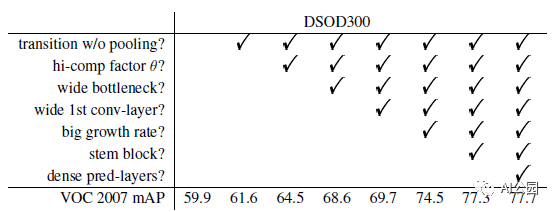
在PASCAL VOC 2007测试集上的消融研究
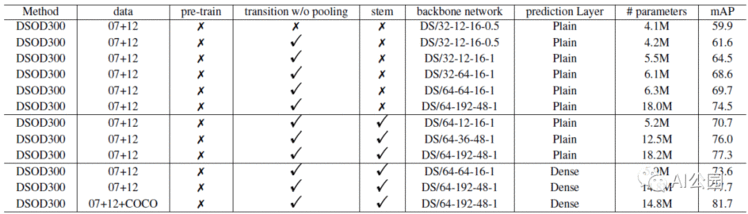
在PASCAL VOC 2007测试集上的消融研究的细节
使用了DSOD300 (输入尺寸为300×300)。
使用VOC 2007训练集和2012训练集(“07+12”)的组合训练集对模型进行训练,并在VOC 2007测试集上进行测试。
DS/A-B-k-θ描述了主干网络的结构。
A表示在第一个卷积层中通道的数量。
B表示在每个bottleneck层(1×1 卷积)中通道的数量
k表示dense blocks中的growth rate。
θ表示在transition层中的压缩因子。
3.1. Dense Blocks的配置
Transition层中的压缩系数:压缩系数θ=1表示transition层没有减少feature map,而θ= 0.5表示减少了一半的feature map。结果表明,θ = 1比θ = 0.5高2.9%。
bottleneck层中的通道数量:更宽的bottleneck层(使用更多通道的响应层)提升了很多(4.1% mAP)。
第一层中的通道数量:第一层中的大的通道数量是有益的,这带来了1.1% mAP的提升。
Growth rate: 大的生长率k要好得多。当将k从16增加到48,bottleneck通道为4k时,观察到有4.8%的mAP改善。
3.2. 设计准则的效果
Proposal-free框架:对于二阶段的Faster R-CNN和R-FCN,对于所有的试过的网络结构(VGGNet, ResNet, DenseNet)训练都没有收敛。
使用SSD,训练能收敛,但是结果差很多 (69.6% for VGGNet)。
深度监督:DSOD300 achieves 77.7% mAP。比SSD300的finetune结果好的多。
Transition w/o Pooling Layer:使用没有池化的Transition的网络结构带来了1.7%的提升。
Stem Block:stem block将结果从74.5%提升到了 77.3%。
Dense Prediction Structure:使用了dense的前端结构的DSOD比原始结构速度稍慢了一些(17.4 fps vs. 20.6 fps),但是将mAP从77.3%提升到了77.7%,同时参数量从18.2M减少到了14.8M。
在ImageNet上预训练会怎么样?在ImageNet上小backbone网络DS/64–12–16–1,能达到66.8% top-1准确率和87.8% top-5准确率。finetune之后,在VOC 2007测试集上达到70.3%的mAP。
对应的从头训练的方案达到了70.7%,略好一点。
3.3. 运行时的分析
使用300×300的输入尺寸,DSOD处理一张图需要48.6ms (20.6 fps),在单个 Titan X GPU上,使用原始的预测结构。使用dense的预测结构时,需要57.5ms (17.4 fps)。
作为对比,R-FCN在用ResNet50时,运行时间为90ms (11 fps),ResNet101时,运行时间为110ms (9 fps)。
SSD300用ResNet101时运行时间为82.6ms (12.1 fps) ,用VGGNet时为21.7ms (46 fps)。
轻量级的DSOD(10.4M参数,不使用任何的加速优化),运行时间为25.8 fps,只掉了1个点的mAP。
4. 实验结果
4.1. PASCAL VOC2007
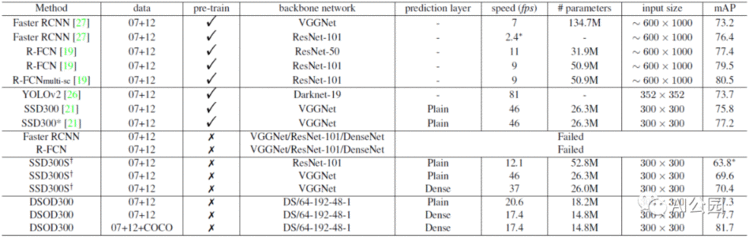
模型是在VOC 2007 trainval和VOC 2012 trainval的联合数据集 (“07+12”)上训练的。
使用的batchsize是128,由于显存不够,所以两个迭代累积一次梯度。
DSOD300使用原始的连接方式达到了77.3%,比SSD300略好,比YOLOv2更好。
DSOD300使用了dense预测结构,提升到了77.7%。
在加入的COCO的训练数据之后,进一步提升到了81.7%。
4.2. PASCAL VOC2012

使用了VOC 2012 trainval和VOC 2007 trainval + test用于训练,在VOC 2012 test上测试。
DSOD300达到76.3% mAP,比SSD300(75.8%),YOLOv2 (73.4%),Faster R-CNN(73.8%)都好。
使用COCO训练,DSOD300 (79.3%) 优于ION(76.4%) 和R-FCN 多尺度(77.6%)。
4.3. MS COCO

在trainval上进行训练。
DSOD300达到了29.3%/47.3% (overall mAP/mAP @ 0.5),比SSD300要好很多。
结果相比单尺度的R-FCN也很有竞争力,接近了使用ResNet101的预训练模型的R-FCN的多尺度模型。
有趣的是,DSOD在0.5IoU上的结果低于R-FCN,但是在[0.5:0.95]上的结果要更好。
这表示了在大的overlap的设置下,DSOD的位置预测比R-FCN更加准确,在小目标上,检测准确率要比R-FCN差也很好解释,因为我们的输出尺寸为300x300,比R-FCN的600x1000要小的多。
5. 讨论
基于上面的结果,进行了一些讨论。
5.1. 更好的模型结构 vs 更多的训练数据
与从大数据中训练出来的复杂模型相比,更好的模型结构可能支持类似或更好的性能。
特别是,在VOC 2007上,DSOD只训练了16551张图像,它的性能比训练了120万+ 16551张图像的模型有竞争力甚至更好。
5.2. 为什么从头训练?
首先,从预先训练的模型领域到目标领域可能有很大的领域差异。
其次,模型微调限制了目标检测网络的结构设计空间。
5.3. 模型的紧密性 vs. 表现
由于dense block的参数效率很高,该模型比大多数其他方法要小得多。
例如,最小的dense模型 (DS/ 64-64-16-1,具有dense的预测层)达到73.6%的mAP,仅有5.9M参数,显示了在低端设备上应用的巨大潜力。
—END—
英文原文:https://sh-tsang.medium.com/review-dsod-learning-deeply-supervised-object-detectors-from-scratch-object-detection-43393dcb31bd
-------------------
END
--------------------
我是王博Kings,985AI博士,华为云专家、CSDN博客专家(人工智能领域优质作者)。单个AI开源项目现在已经获得了2100+标星。现在在做AI相关内容,欢迎一起交流学习、生活各方面的问题,一起加油进步!
我们微信交流群涵盖以下方向(但并不局限于以下内容):人工智能,计算机视觉,自然语言处理,目标检测,语义分割,自动驾驶,GAN,强化学习,SLAM,人脸检测,最新算法,最新论文,OpenCV,TensorFlow,PyTorch,开源框架,学习方法...
这是我的私人微信,位置有限,一起进步!

王博的公众号,欢迎关注,干货多多
王博Kings的系列手推笔记(附高清PDF下载):
博士笔记 | 周志华《机器学习》手推笔记第一章思维导图
博士笔记 | 周志华《机器学习》手推笔记第二章“模型评估与选择”
博士笔记 | 周志华《机器学习》手推笔记第三章“线性模型”
博士笔记 | 周志华《机器学习》手推笔记第四章“决策树”
博士笔记 | 周志华《机器学习》手推笔记第五章“神经网络”
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(上)
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(下)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(上)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(下)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(上)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(下)
博士笔记 | 周志华《机器学习》手推笔记第九章聚类
博士笔记 | 周志华《机器学习》手推笔记第十章降维与度量学习
博士笔记 | 周志华《机器学习》手推笔记第十一章稀疏学习
博士笔记 | 周志华《机器学习》手推笔记第十二章计算学习理论
博士笔记 | 周志华《机器学习》手推笔记第十三章半监督学习
博士笔记 | 周志华《机器学习》手推笔记第十四章概率图模型

点分享

点收藏

点点赞

点在看







 京公网安备 11010802041100号
京公网安备 11010802041100号